Multi-Server Mode (Horizontal Scalability)
Multi-server mode description
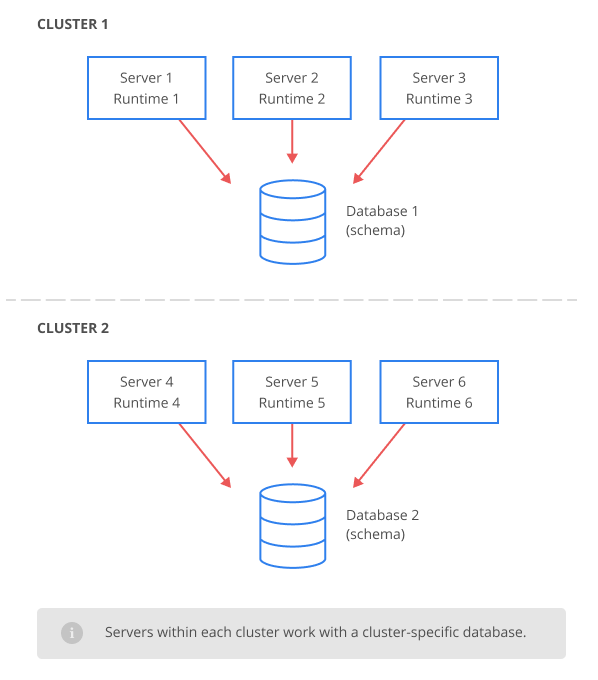
If you are going to run several Workflow Server instances connected to the same database, the multi-server mode should be used. This mode is only available with the Ultimate license. The Workflow Server instances do not know anything about each other; they only share a common database (or database scheme). All instances are equal, none of them is special, and therefore, at least one working instance is sufficient for the health of your cluster. The Workflow Server does not provide load balancing tools; the balancer should be external, choose the one that you are able to configure.
Configuring Workflow Server
The Workflow Server configuration to work in the multi-server mode is quite simple. The only requirement is to include the following line in
the server configuration file: config.json.
{
"IsMultiServer": true
}
If the server is started with this setting, it will work in the multi-server mode. In this case, the runtime identifier will be generated
automatically. You can also explicitly specify the runtime identifier in the config.json:
{
"RuntimeId": "Unique Runtime Identifier"
}
If the runtime identifier is not specified, then the system generates a file with a random (GUID) runtime identifier. The path to this file can be defined as follows:
{
"RuntimeIdFile": "C:/SomeDirectory/runtimeid.config"
}
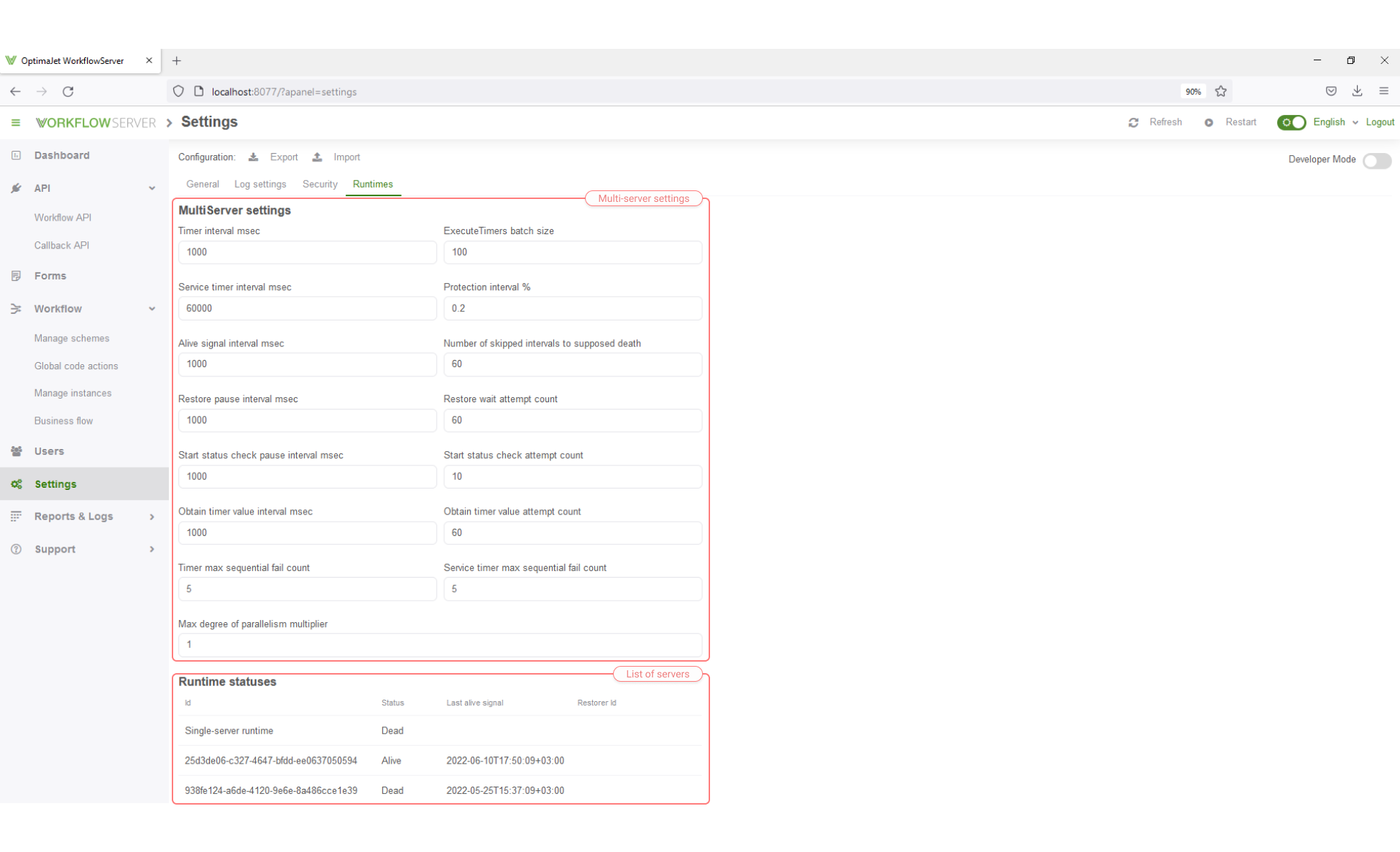
The rest of the multi-server settings should be defined in the Settings page in the Runtimes tab. There, the list of settings, their values, can be reviewed, and might be changed the settings to apply to each server in the cluster. The list of all servers, either currently working or ever worked before, is also available.
Each instance of Workflow Server contains exactly one Workflow Runtime.
Multi-server Settings
The multi-server mode settings can be changed in the Runtimes tab in the Settings page of Workflow Server. The following options are available:
int TimerInterval = 1000- the system timer interval to handle process timers, in milliseconds.int TimerMaxSequentialFailCount = 5- if an unhandled exception occurs during the system timer execution, and repeats consecutively the number of times specified by this setting, the timer gets disabled.int ExecuteTimersBatchSize = 100- the system timer handles process timers in batches; it is the size of such a batch.int ServiceTimerInterval = 60000- the system service timer interval. This timer starts recovery processes after a failure. See in detail below.int ServiceTimerMaxSequentialFailCount = 5- if an unhandled exception occurs during the system service timer execution, and repeats consecutively the number of times specified by this setting, the service timer gets disabled.ProtectionIntervalInPercents { get; set; } = 0.2- the value of the protection interval, necessary so that the system timers of different servers do not interfere with each other. See the timers diagram below.AliveSignalInterval = 1000- the interval to report that a server is still running, in milliseconds.int NumberOfSkippedIntervalsToSupposeDeath { get; set; } = 60- the number of missed report signals that a server is still running, after which the server is declared Terminated, and the data become subject for recovery procedures.int RestorePauseInterval { get; set; } = 1000- if a server starts and finds out that another server has begun to restore its data, then it will wait for its recovery, standing by at the indicated interval in milliseconds.int RestoreWaitAttemptCount { get; set; } = 60- if a server starts and finds out that another server has begun to recover its data, it will wait for its recovery; this is the maximum number of attempts to wait for the recovery. If the actual number exceeds the maximum, the server will shut down.int StartStatusCheckPauseInterval { get; set; } = 1000- if a server starts and finds out that another server has begun to change its state, then it will wait for the new state, standing by at the indicated interval in milliseconds.int StartStatusCheckAttemptCount { get; set; } = 10- if a server starts and finds out that another server has begun to change its state, then it will wait for the new state; this is the maximum number of attempts to wait for the new state.int ObtainTimerValueInterval { get; set; } = 1000- servers are integrated into the timers diagram to process the timers in turn. If a server cannot get the time value for its system timer to start by the schedule, then it will wait during the indicated interval in milliseconds.int ObtainTimerValueAttemptCount { get; set; } = 60- the number of attempts to get the next time value for the system timer to start. After exceeding the maximum number of attempts, the server will shut down.int MaxDegreeOfParallelismMultiplier { get; set; } = 1- each server tries to process timers and recovery processes in parallel; the degree of parallelism is defined as the number of available processor cores multiplied by this value.
States of Runtimes
In Workflow Server, the runtime data can be reviewed in the Runtimes tab in the Settings page.
The Workflow Runtime might have one of the following states:
- Dead - the runtime was correctly turned off and not working at the moment. No recovery required.
- Terminated - the runtime was turned off, but the recovery procedure is required.
- SelfRestore - the runtime has restarted and undergoing the self-restore procedure.
- Restore - the runtime data is being restored by another server, the runtime itself is not working.
- Alive - the runtime is alive if the current time does not exceed the
value
LastAliveSignal + AliveSignalInterval * NumberOfSkippedIntervalsToSupposeDeath, that is, the runtime has lately shown signs of life. If this condition is not met, then the runtime is declared Terminated. - Single - a special state for the single-server runtime, similar to Alive.
Features of Timers
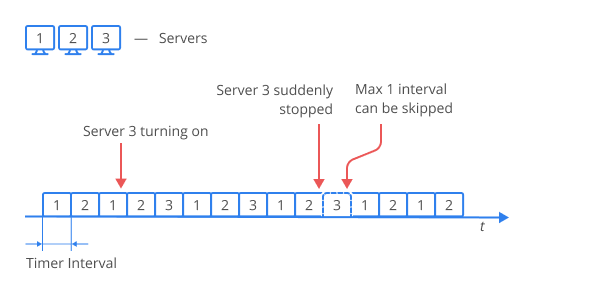
The timers system for the multi-server mode is designed with the following features:
- it guarantees that no timer will start before the appointed time, provided that at least one server is running.
- the timer response time may be longer than the assigned value, but the system tries to minimize the delay.
- if all servers have shut down, but then at least one turns on, all of the timers will be processed.
- the servers process the timers in turn, in order to minimize the performance drop due to the competition between the servers, and to keep the system alive, even if several servers have failed.
Below is the diagram of timers in the multi-server mode, if an additional server turns on, or if it suddenly turns off.
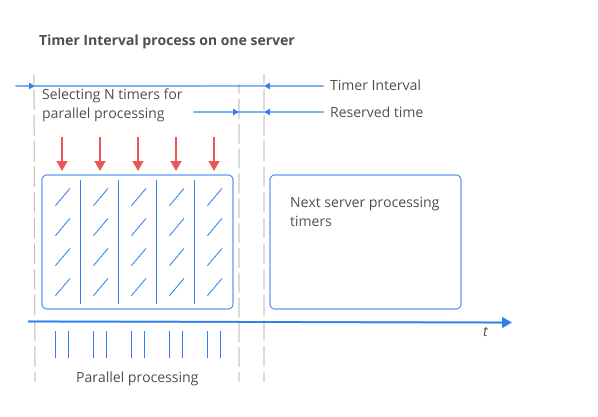
Inside each server, the following occurs: when it is time to start processing the timers, it selects a batch of timers, with the batch size
less or equal to ExecuteTimersBatchSize. The timers are processed in parallel. After processing the chosen timers, the server finds out
whether it can process more of them; that is, if there is any time left before another server starts processing the timers. At the same
time, the server tries not to use the time interval TimerInterval * ProtectionIntervalInPercents, considering it an untouchable reserve.
Thus, the server tries to process the maximum possible number of timers during the interval equal
to TimerInterval * (1 - ProtectionIntervalInPercents). The batch size of the timers being processed does not
exceed ExecuteTimersBatchSize. After the server stops processing the timers, it determines the next time the system timer to be activated,
and sets the system timer for this time.
Process Association with Workflow Runtime
How the process is associated with the runtime, it should be reviewed in order to understand the recovery procedure. Since, if the runtime (or the server instance) turns off, you should restore the processes that belong to this particular instance that has turned off. Here, a very simple rule.
- If a process is inactive - Idled or Finalized - it is not associated to anything.
- If a process is in the Running status, then it belongs to the runtime (or the server instance) that has set this status.
Service Timer and Recovery Procedure
The system service timer works according to the same diagram as the system timer, but taking into account the ServiceTimerInterval
setting. If the server stops incorrectly, there can appear processes stuck in the Running status (the statuses of processes are
described here). The Running status will prevent further manipulation
of the process, therefore, it must be reset. This procedure is started by the service timer. This timer serves for the runtimes that require
tidying up.
The following priorities of the Workflow Runtimes selection for recovery are set:
- a runtime that was being restored by this server before, but the recovery was interrupted for some reason.
- a runtime with the Single state.
- a runtime with the Alive state but without any signs of life during the interval equal
to
AliveSignalInterval * NumberOfSkippedIntervalsToSupposeDeath, or in the Terminated state. The runtime that has remained silent the longest of all is the first runtime to be processed.
The recovery procedure is also started by the server itself at startup if it detects that it was incorrectly stopped.
The recovery procedure and its customization are described here.